http协议
[TOC]
http协议 - 应用层
超文本传输协议(HTTP)的设计目的是保证客户机与服务器之间的通信。
HTTP 的工作方式是客户机与服务器之间的请求-应答协议。
web 浏览器可能是客户端,而计算机上的网络应用程序也可能作为服务器端。
举例:客户端(浏览器)向服务器提交 HTTP 请求;服务器向客户端返回响应。响应包含关于请求的状态信息以及可能被请求的内容。
请求消息(Request)
请求消息(Request) - 浏览器给服务器发送的数据
客户端发送一个HTTP请求到服务器的请求消息包括四部分: 请求行, 请求头, 空行, 请求数据
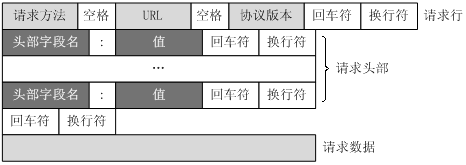
- 请求行: 说明请求类型, 要访问的资源, 以及使用的http版本
- 请求头: 说明服务器要使用的附加信息
- 空行: 空行是必须要有的, 即使没有请求数据
- 请求数据: 也叫主体, 可以添加任意的其他数据
请求方法
HTTP1.1的五种请求方法
下面的表格列出了其他一些 HTTP 请求方法:
| 方法 | 描述 |
|---|---|
| GET | 请求指定的页面信息数据,并返回实体主体。 |
| POST | 向指定资源提交数据进行处理的请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 |
| HEAD | 类似于get请求,但只返回 HTTP 报头,不返回文档主体,用于获取报头。 |
| PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| DELETE | 请求服务器删除指定的页面。 |
| OPTIONS | 返回服务器支持的 HTTP 方法。 |
| CONNECT | 把请求连接转换到透明的 TCP/IP 通道。 |
在客户机和服务器之间进行请求-响应时,两种最常被用到的方法是:GET 和 POST。
- GET - 从指定的资源请求数据。
- POST - 向指定的资源提交要被处理的数据。
GET 方法
使用get方法请求数据:
GET /test.txt HTTP/1.1 // 请求行 Host: localhost:2222 // 请求头 User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:24.0) Gecko/201001 01 Firefox/24.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/ *;q=0.8 Accept-Language: zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3 Accept-Encoding: gzip, deflate Connection: keep-alive If-Modified-Since: Fri, 18 Jul 2014 08:36:36 GMT\r\n // 空行 请求数据(可以为空) // 请求数据
请注意,查询字符串(名称/值对)是在 GET 请求的 URL 中发送的:
/test/demo_form.asp?name1=value1&name2=value2
有关 GET 请求的其他一些注释:
- GET 请求可被缓存
- GET 请求保留在浏览器历史记录中
- GET 请求可被收藏为书签
- GET 请求不应在处理敏感数据时使用
- GET 请求有长度限制
- GET 请求只应当用于取回数据
请求示例:
当在浏览器地址栏输入http://192.168.43.118:3434/text.txt向服务器发送请求:
GET /test.txt HTTP/1.1 // 请求行,要访问资源 /test.txt Host: 192.168.43.118:3434 // 请求头 Connection: keep-alive DNT: 1 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9 Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9,en;q=0.8 // 空行 请求数据空(可以为空) // 请求数据
百度请求示例:
GET / HTTP/1.1 // 请求行,要访问资源 / Host: www.baidu.com // 请求头 Connection: keep-alive Cache-Control: max-age=0 DNT: 1 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9 Sec-Fetch-Site: none Sec-Fetch-Mode: navigate Sec-Fetch-User: ?1 Sec-Fetch-Dest: document Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9,en;q=0.8 Cookie: BIDUPSID=F59F13A20C5C1BD4105595034149E154; PSTM=1592187477; BAIDUID=F59F13A20C5C1BD4F2D6FC754668989A:FG=1; BD_UPN=123353; BD_HOME=1; H_PS_PSSID=1423_32124_32140_32045_32231_32145_32257; delPer=0; BD_CK_SAM=1; PSINO=5; ZD_ENTRY=empty // 空行 请求数据空(可以为空) // 请求数据
浏览器地址栏: 192.168.1.115/hello.c
浏览器封装一个http请求协议?? get /hello.c http/1.1
POST 方法
使用post方法请求数据:
POST HTTP/1.1 // 请求行 Host: localhost:2222 // 请求头 User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:24.0) Gecko/201001 01 Firefox/24.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/ *;q=0.8 Accept-Language: zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3 Accept-Encoding: gzip, deflate Connection: keep-alive If-Modified-Since: Fri, 18 Jul 2014 08:36:36 GMT // 空行 user=詹姆斯&pwd=James&sex=男 // 请求数据
请注意,查询字符串(名称/值对)是在 POST 请求的 HTTP 消息主体中发送的:
POST /test/demo_form.asp HTTP/1.1
Host: w3schools.com
name1=value1&name2=value2
有关 POST 请求的其他一些注释:
- POST 请求不会被缓存
- POST 请求不会保留在浏览器历史记录中
- POST 不能被收藏为书签
- POST 请求对数据长度没有要求
比较 GET 与 POST
下面的表格比较了两种 HTTP 方法:GET 和 POST。
| GET | POST | |
|---|---|---|
| 后退按钮/刷新 | 无害 | 数据会被重新提交(浏览器应该告知用户数据会被重新提交)。 |
| 书签 | 可收藏为书签 | 不可收藏为书签 |
| 缓存 | 能被缓存 | 不能缓存 |
| 编码类型 | application/x-www-form-urlencoded | application/x-www-form-urlencoded 或 multipart/form-data。为二进制数据使用多重编码。 |
| 历史 | 参数保留在浏览器历史中。 | 参数不会保存在浏览器历史中。 |
| 对数据长度的限制 | 是的。当发送数据时,GET 方法向 URL 添加数据;URL 的长度是受限制的(URL 的最大长度是 2048 个字符)。 | 无限制。 |
| 对数据类型的限制 | 只允许 ASCII 字符。 | 没有限制。也允许二进制数据。 |
| 安全性 | 与 POST 相比,GET 的安全性较差,因为所发送的数据是 URL 的一部分。在发送密码或其他敏感信息时绝不要使用 GET ! | POST 比 GET 更安全,因为参数不会被保存在浏览器历史或 web 服务器日志中。 |
| 可见性 | 数据在 URL 中对所有人都是可见的。 | 数据不会显示在 URL 中。 |
响应消息(Response)
响应消息(Response) - 服务器给浏览器发送的数据 响应消息四部分: 状态行(必须), 消息报头, 空行(必须), 响应正文
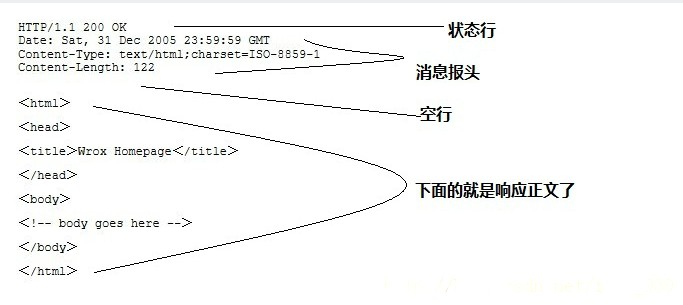
- 状态行: 包括http协议版本号, 状态码, 状态信息
- 消息报头: 说明客户端要使用的一些附加信息
- 空行: 空行是必须要有的
- 响应正文: 服务器返回给客户端的文本信息
HTTP/1.1 200 Ok // 状态行 Server: micro_httpd // 消息报头 Date: Fri, 18 Jul 2014 14:34:26 GMT Content-Type: text/plain; charset=utf-8 (重要,响应的数据类型) Content-Length: 32 //响应的数据的长度 Content-Language: zh-CN Last-Modified: Fri, 18 Jul 2014 08:36:36 GMT Connection: close // 空行 xxx响应正文 // 响应正文
百度响应示例:
HTTP/1.1 200 OK // 状态行 Cache-Control: private // 消息报头 Connection: keep-alive Content-Encoding: gzip Content-Type: html;charset=utf-8 Date: Fri, 10 Jul 2020 04:29:01 GMT Expires: Fri, 10 Jul 2020 04:28:51 GMT Server: BWS/1.1 Set-Cookie: BDSVRTM=0; path=/ Set-Cookie: BD_HOME=1; path=/ Set-Cookie: H_PS_PSSID=1423_32124_32140_32045_32231_32145_32257; path=/; domain=.baidu.com Strict-Transport-Security: max-age=172800 Traceid: 1594355341057394381816994770365719048149 X-Ua-Compatible: IE=Edge,chrome=1 Transfer-Encoding: chunked // 空行 <!DOCTYPE html> // 响应正文 <html lang="zh-CN"> <head> <meta charset="UTF-8"> <title>百度一下</title> </head> <body> <p> 这是百度的主页面 </p> </body> </html>
http状态码
当浏览器从 web 服务器请求服务时,可能会发生错误。
从而有可能会返回下面的一系列状态消息:
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx:指示信息
表示请求已接收,继续处理
2xx:成功
表示请求已被成功接收、理解、接受
3xx:重定向
要完成请求必须进行更进一步的操作
4xx:客户端错误
请求有语法错误或请求无法实现
5xx:服务器端错误
服务器未能实现合法的请求
常见状态码:
| 状态码 | 描述 |
|---|---|
| 200 OK | 客户端请求成功 |
| 400 Bad Request | 客户端请求有语法错误,不能被服务器所理解 |
| 401 Unauthorized | 请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用 |
| 403 Forbidden | 服务器收到请求,但是拒绝提供服务 |
| 404 Not Found | 请求资源不存在,如输入了错误的URL |
| 500 Internal Server Error | 服务器发生不可预期的错误 |
| 503 Server Unavailable | 服务器当前不能处理客户端的请求,一段时间后可能恢复正常 |
http中文件类型
普通文件: text/plain; charset=utf-8 .html: text/html; charset=utf-8 .jpg : image/jpeg .gif : image/gif .png: image/png .wav: audio/wav .avi : video/x-msvideo .mov: video/quicktime .mp3: audio/mpeg
字符集
charset=iso-8859-1 西欧的编码,说明网站采用的编码是英文; charset=gb2312 说明网站采用的编码是简体中文; charset=utf-8 代表世界通用的语言编码;可以用到中文、韩文、日文等世界上所有语言编码上 charset=big5 说明网站采用的编码是繁体中文;
URL
URL组成
统一资源定位器(URL) - Uniform Resource Locator
统一资源定位器(URL)用于定位万维网上的文档(或其他数据)。
URL 也被称为网址。URL 可以由单词组成,比如 “baidu.com”,或者是因特网协议(IP)地址:192.168.1.253。
当您点击 HTML 页面中的某个链接时,对应的 标签指向万维网上的一个地址。
scheme://host.domain:port/path/filename
https://www.baidu.com:443/
- scheme - 定义因特网服务的类型。最常见的类型是 http,https,ftp
- host - 定义域主机(http 的默认主机是 www)
- domain - 定义因特网域名,比如 w3school.com.cn
- :port - 定义主机上的端口号(http 的默认端口号是 80)
- path - 定义服务器上的路径(如果省略,则文档必须位于网站的根目录中)。
- filename - 定义文档/资源的名称
一个完整的URL例子:
一个完整的URL包括:协议部分、域名部分、端口部分、虚拟目录部分、文件名部分、参数部分、锚部分

1.协议:模式/协议(scheme),在Internet中可使用多种协议,如HTTP,FTP等。在”HTTP”后面的“//”为分隔符
2.域名:也可使用IP地址作为域名使用。
3.端口:不是一个URL必须的部分,如果省略端口部分,将采用默认端口。
4.虚拟目录:从域名后的第一个“/”开始到最后一个“/”为止。虚拟目录不是一个URL必须的部分。
5.文件名:从域名后的最后一个“/”至“?”(或“#”或至结束)为止,是文件名部分。文件名部分不是一个URL必须的部分,如果省略该部分,则使用默认的文件名。
7.参数:从“?”开始到“#”(或至结束)为止之间的部分为参数部分,又称搜索部分、查询部分。参数间用“&”作为分隔符。
6.锚:或称片段(fragment),HTTP请求不包括锚部分,从“#”开始到最后,都是锚部分。本例中的锚部分是“r_70732423“。锚部分不是一个URL必须的部分。
锚点作用:打开用户页面时滚动到该锚点位置。如:一个html页面中有一段代码【
基本URL包含模式(或称协议)、服务器名称(或IP地址)、路径和文件名,如下:
协议://授权/路径?查询
完整的、带有授权部分的普通统一资源标志符语法看上去如下:
协议://用户名:密码@子域名.域名.顶级域名:端口号/目录/文件名.文件后缀?参数=值#标志
URL 编码
URL 编码会将字符转换为可通过因特网传输的格式。
URL 只能使用 ASCII 字符集来通过因特网进行发送。
由于 URL 常常会包含 ASCII 集合之外的字符,URL 必须转换为有效的 ASCII 格式。
URL 编码使用 "%" 其后跟随几位的十六进制数来替换非 ASCII 字符。
URL 不能包含空格。URL 编码通常使用 + 来替换空格。
你好 ––>> %e4%bd%a0%e5%a5%bd
一般来说,URL只能使用英文字母、阿拉伯数字和某些标点符号,不能使用其他文字和符号。只有字母和数字[0-9a-zA-Z]、一些特殊符号$-_.+!*'(),[不包括双引号]、以及某些保留字,才可以不经过编码直接用于URL。
GET和POST方法的编码,用的是网页的编码。编码方法由网页的编码决定,也就是由HTML源码中字符集的设定决定。
<meta http-equiv="Content-Type" content="text/html;charset=xxxx">
如果上面这一行最后的charset是UTF-8,则URL就以UTF-8编码;如果是GB2312,URL就以GB2312编码。
实现http服务器
- 编写函数解析http请求 ○ GET /hello.html HTTP/1.1\r\n ○ 将上述字符串分为三部分解析出来
- 编写函数根据文件后缀,返回对应的文件类型
- sscanf - 读取格式化的字符串中的数据
○ 使用正则表达式拆分
○
[^ ]的用法 - 通过浏览器请求目录数据 ○ 读指定目录内容 ○ opendir ○ readdir ○ closedir ○ scandir - 扫描dir目录下(不包括子目录)内容
- http中数据特殊字符编码解码问题 ○ 编码 ○ 解码